 ⛶ bấm để phóng to
⛶ bấm để phóng to
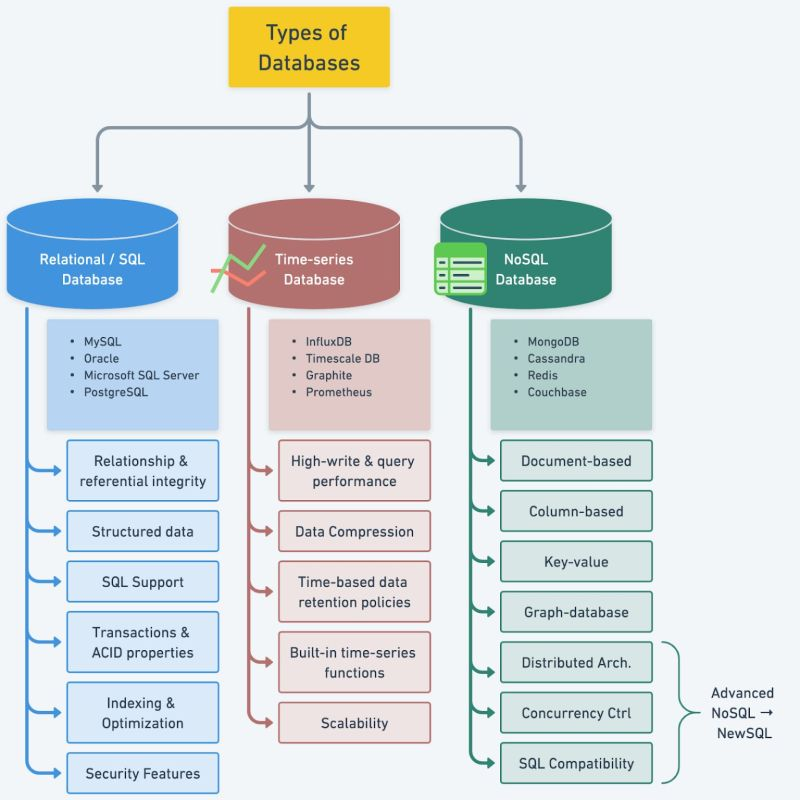
SQL và NoSQL
Database SQL (quan hệ) lưu dữ liệu thành bảng có schema cố định, các bảng nối nhau bằng khóa. Nó mạnh ở truy vấn phức tạp và đảm bảo toàn vẹn dữ liệu. PostgreSQL và MySQL là ví dụ.
Database NoSQL gồm nhiều loại: document (MongoDB), key-value (Redis), wide-column (Cassandra), graph (Neo4j). Chúng bỏ schema cứng để đổi lấy tốc độ và scale ngang. Dữ liệu thường lưu phi chuẩn hóa, gom sẵn thứ hay đọc cùng nhau vào một chỗ.
A SQL (relational) database stores data in tables with a fixed schema, joined by keys. It is strong at complex queries and at enforcing data integrity. PostgreSQL and MySQL are examples.
A NoSQL database comes in several kinds: document (MongoDB), key-value (Redis), wide-column (Cassandra), graph (Neo4j). They drop the rigid schema to gain speed and horizontal scale. Data is often denormalized, grouping what you read together into one place.
⛶ bấm để phóng to
Chuẩn hóa và phi chuẩn hóa
SQL tách dữ liệu thành nhiều bảng để tránh trùng lặp, gọi là chuẩn hóa. Lúc đọc, một truy vấn JOIN ghép các bảng lại. Ghi gọn và nhất quán, nhưng join nhiều bảng lớn thì tốn.
NoSQL document thường phi chuẩn hóa: lưu sẵn dữ liệu liên quan lồng trong một document, nên một lần đọc lấy hết, không cần join. Đổi lại dữ liệu bị trùng và cập nhật phải sửa nhiều nơi. Đây là đánh đổi giữa chuẩn hóa để ghi gọn và phi chuẩn hóa để đọc nhanh.
SQL splits data into many tables to avoid duplication, called normalizing. At read time, a query JOINs the tables back together. Writes stay clean and consistent, but joining large tables is expensive.
A NoSQL document store usually denormalizes: it nests related data inside one document, so a single read fetches everything with no join. The price is duplicated data and updates that must touch many places. This is the trade-off between normalizing for clean writes and denormalizing for fast reads.
 ⛶ bấm để phóng to
⛶ bấm để phóng to
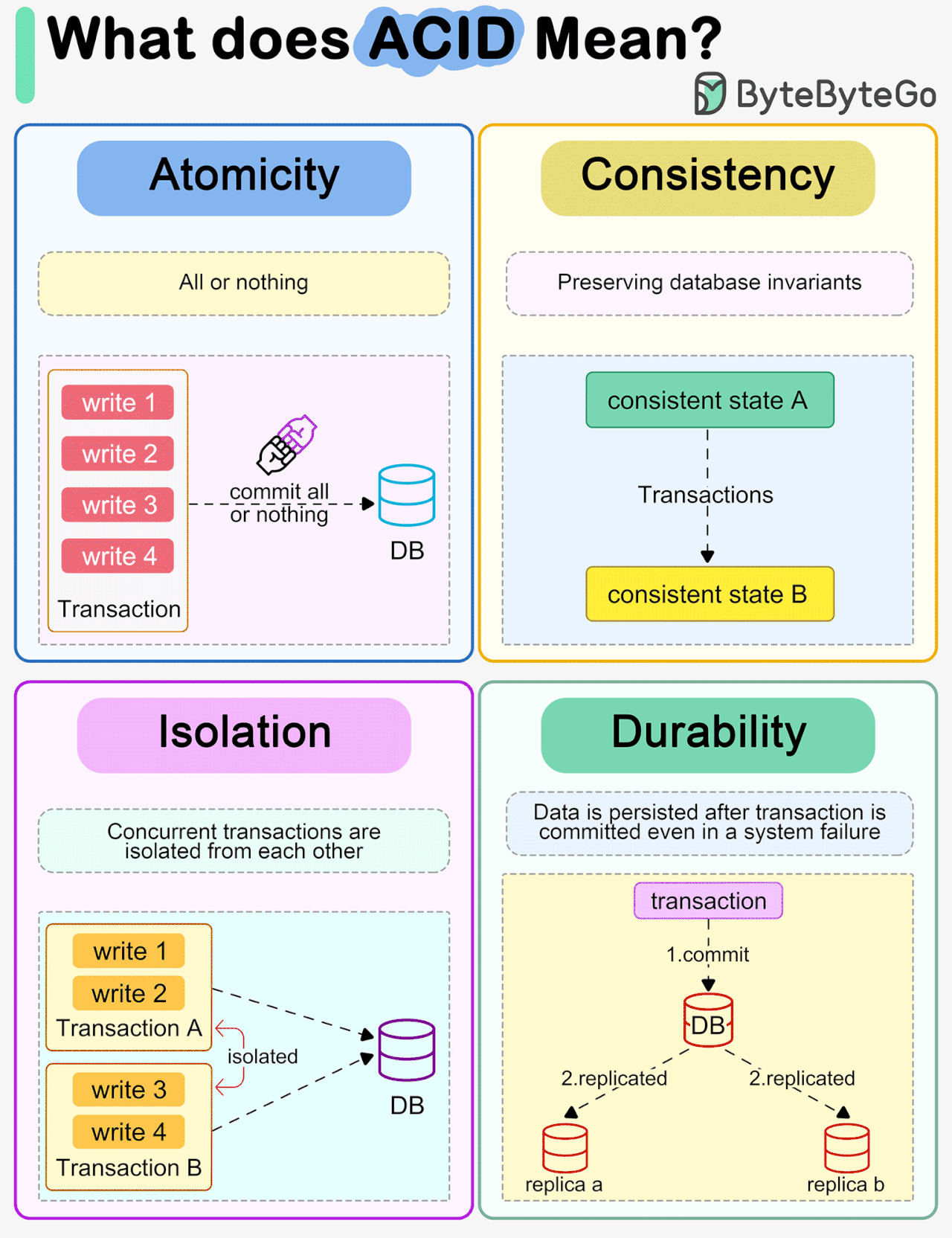
ACID
ACID là bốn đảm bảo của một giao dịch database. Atomicity: cả nhóm thao tác hoặc xong hết hoặc không gì cả. Consistency: dữ liệu luôn hợp lệ theo ràng buộc. Isolation: các giao dịch chạy song song không giẫm lên nhau. Durability: đã commit thì còn mãi, kể cả khi mất điện.
SQL database truyền thống đảm bảo ACID mạnh. Đây là lý do hệ tài chính chọn chúng. Nhiều NoSQL nới lỏng ACID để đổi lấy tốc độ và scale, chỉ đảm bảo eventual consistency.
ACID is four guarantees of a database transaction. Atomicity: the group of operations either all complete or none do. Consistency: data always stays valid against its constraints. Isolation: concurrent transactions do not step on each other. Durability: once committed, it survives even a power loss.
Traditional SQL databases provide strong ACID. This is why financial systems choose them. Many NoSQL databases relax ACID for speed and scale, guaranteeing only eventual consistency.
⛶ bấm để phóng to
Transaction và atomicity
Chuyển tiền gồm hai bước: trừ tài khoản A, cộng tài khoản B. Nếu chỉ chạy một nửa rồi server chết, tiền bốc hơi. Atomicity chặn điều đó.
Ta bọc các bước trong một transaction (giữa BEGIN và COMMIT). Nếu bất kỳ bước nào lỗi, database rollback toàn bộ, trả về như chưa làm gì. Không bao giờ có trạng thái trừ mà không cộng. Đây là nền tảng mọi hệ thanh toán dựa vào.
A transfer has two steps: debit account A, credit account B. If only half runs and the server dies, money vanishes. Atomicity prevents that.
We wrap the steps in a transaction (between BEGIN and COMMIT). If any step fails, the database rolls back everything, leaving it as if nothing happened. There is never a debit without a matching credit. This is the foundation every payment system relies on.
 ⛶ bấm để phóng to
⛶ bấm để phóng to
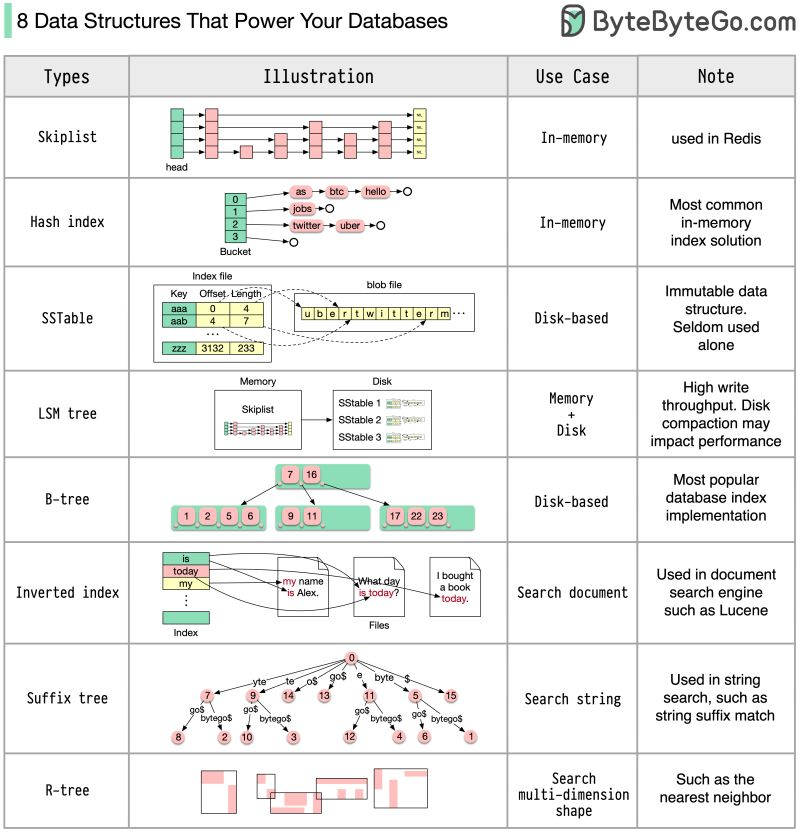
Index: B-tree vs LSM-tree
Index giúp database tìm hàng mà không quét cả bảng. Không có index, một truy vấn phải đọc từng hàng (full scan). Có index, nó nhảy thẳng tới nơi cần.
Hai cấu trúc index phổ biến. B-tree tối ưu cho đọc và truy vấn khoảng, là mặc định của SQL. LSM-tree tối ưu cho ghi nhiều, ghi tuần tự rồi gộp sau, dùng trong Cassandra và RocksDB. Đọc nhiều thì B-tree, ghi nhiều thì LSM.
An index lets a database find rows without scanning the whole table. Without one, a query reads every row (a full scan). With one, it jumps straight to what it needs.
Two common index structures. A B-tree is optimized for reads and range queries, the SQL default. An LSM-tree is optimized for heavy writes, writing sequentially then merging later, used in Cassandra and RocksDB. Read-heavy favors B-tree, write-heavy favors LSM.
⛶ bấm để phóng to
Index có giá của nó
Index làm truy vấn đọc nhanh hơn rất nhiều, nhưng không miễn phí. Mỗi index tốn thêm dung lượng. Mỗi lần ghi phải cập nhật cả index, nên ghi chậm hơn. Vì vậy chỉ đánh index lên cột thật sự hay dùng để lọc hoặc sắp xếp.
Khi một truy vấn chậm, công cụ như EXPLAIN cho thấy database quét toàn bảng (full scan) hay dùng index. Thấy full scan trên bảng lớn là dấu hiệu cần thêm index đúng cột. Đây là bước tối ưu đầu tiên cho hầu hết truy vấn chậm.
An index makes reads much faster, but it is not free. Each index costs extra storage. Every write must also update the index, so writes get slower. So only index columns you truly use for filtering or sorting.
When a query is slow, a tool like EXPLAIN shows whether the database does a full scan or uses an index. A full scan on a large table is a sign you need the right index. This is the first tuning step for most slow queries.
 ⛶ bấm để phóng to
⛶ bấm để phóng to
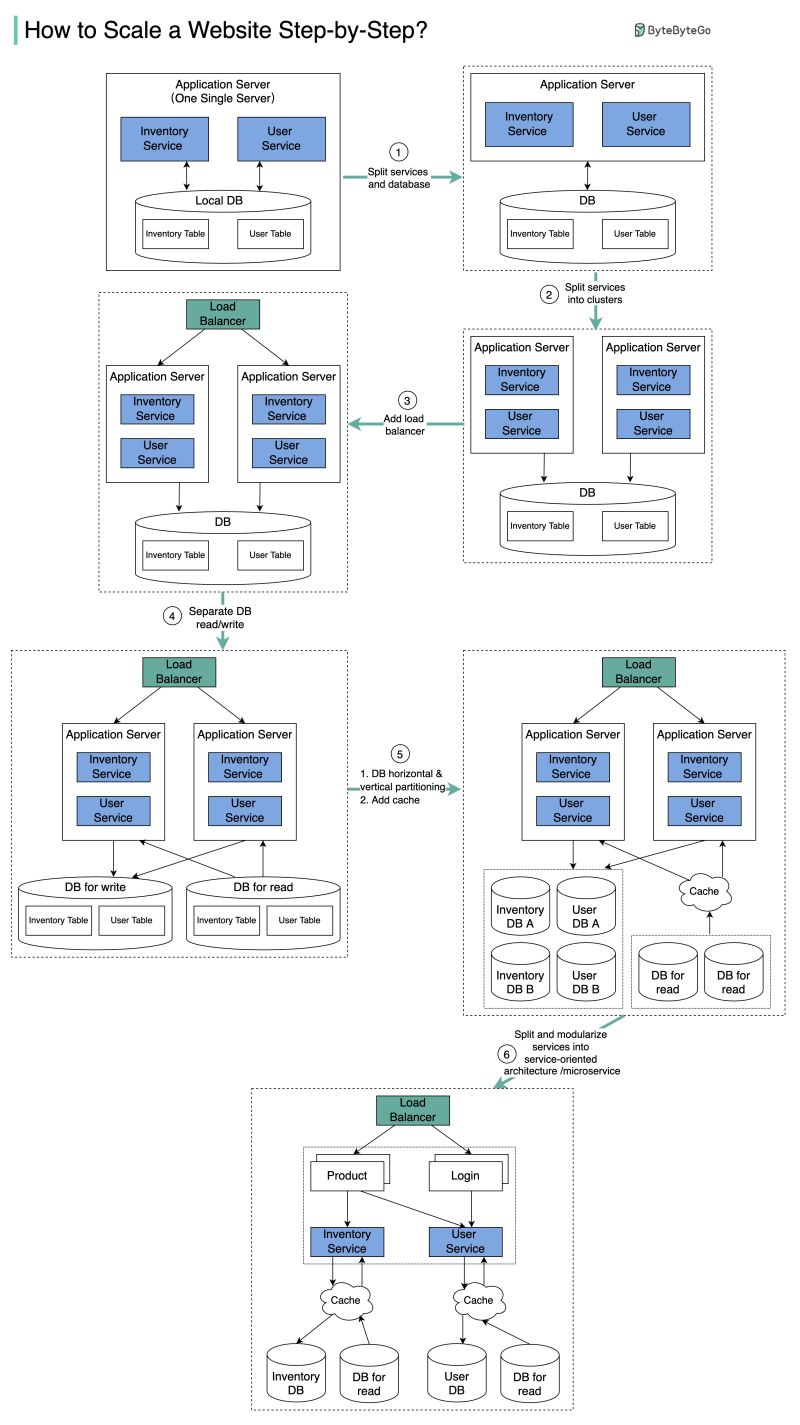
Primary, replica và read/write split
Một database thường có một primary nhận mọi lệnh ghi và nhiều replica nhận lệnh đọc. Sao chép dữ liệu từ primary sang replica gọi là replication. Cho ghi vào primary và chia đọc sang các replica gọi là read/write split. Nó giúp chịu tải đọc lớn và có bản dự phòng khi primary chết.
Replication có hai kiểu. Đồng bộ chờ replica xác nhận trước khi báo ghi xong, an toàn mà chậm. Bất đồng bộ báo xong ngay, nhanh mà replica trễ một nhịp. Độ trễ đó là replication lag: vừa ghi xong mà đọc ngay từ replica có thể thấy dữ liệu cũ. Cần dữ liệu mới ngay thì đọc từ primary.
A database usually has one primary taking all writes and several replicas taking reads. Copying data from primary to replicas is called replication. Sending writes to the primary and spreading reads across replicas is a read/write split. It handles heavy read load and gives a backup when the primary dies.
Replication has two modes. Synchronous waits for a replica to confirm before reporting the write done, safe but slow. Asynchronous reports done immediately, fast but the replica trails by a moment. That delay is replication lag: reading from a replica right after a write may show stale data. When you need fresh data, read from the primary.
 ⛶ bấm để phóng to
⛶ bấm để phóng to
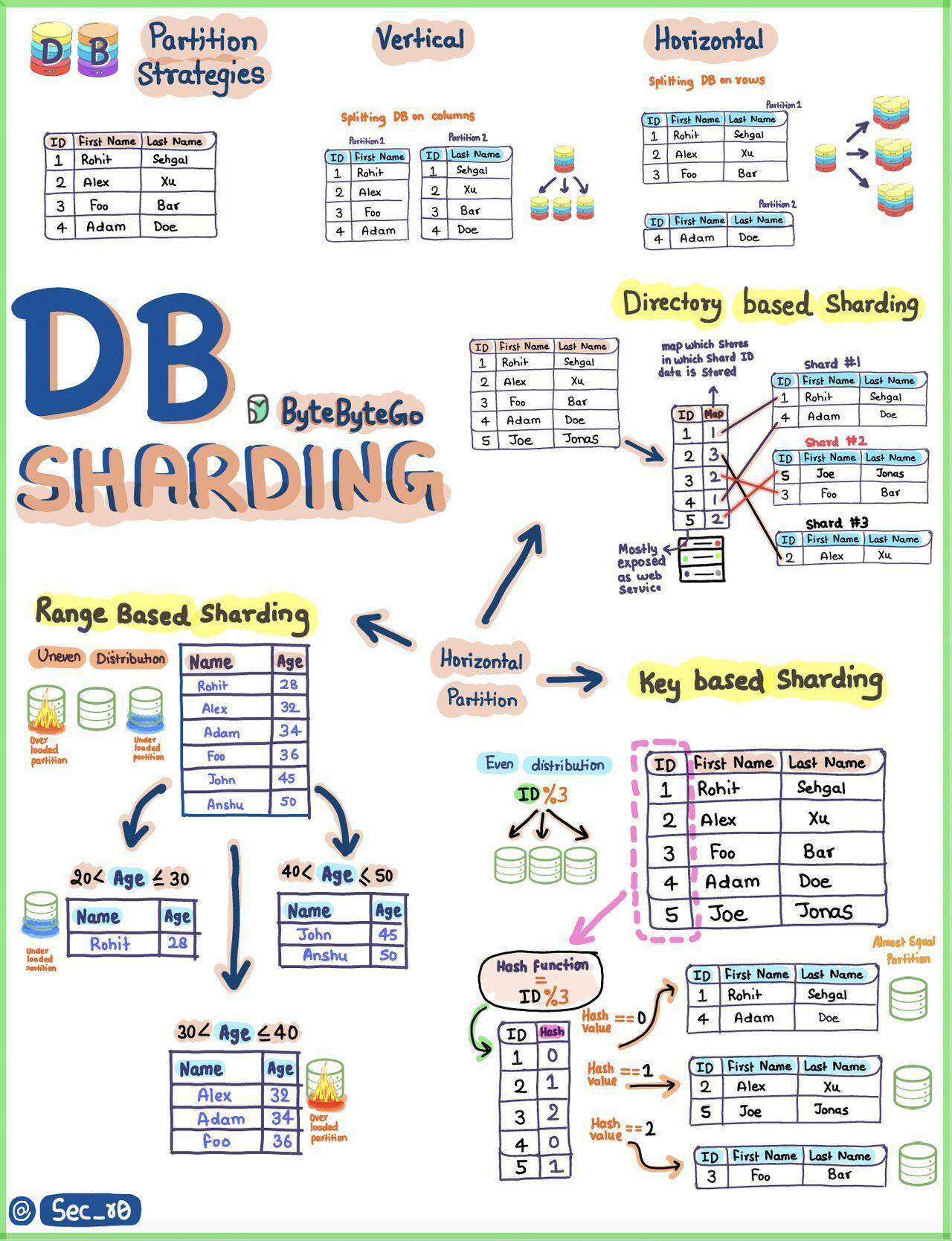
Sharding: chia dữ liệu theo khóa
Khi một database lớn quá sức một máy, ta shard: chia dữ liệu thành nhiều mảnh, mỗi mảnh ở một máy. Một shard key quyết định hàng nào đi máy nào.
Chia theo hash của khóa rải đều dữ liệu nhưng khó truy vấn khoảng. Chia theo range dễ truy vấn khoảng nhưng dễ tạo hot shard khi dữ liệu dồn một vùng. Sharding mở khóa scale ngang. Đổi lại join và transaction xuyên shard phức tạp hơn nhiều.
When one database is too big for a single machine, we shard it: split the data into pieces, each on its own machine. A shard key decides which row goes to which machine.
Splitting by a hash of the key spreads data evenly but makes range queries hard. Splitting by range makes range queries easy but invites a hot shard when data piles into one region. Sharding unlocks horizontal scale. The price is that cross-shard joins and transactions become much harder.
 ⛶ bấm để phóng to
⛶ bấm để phóng to
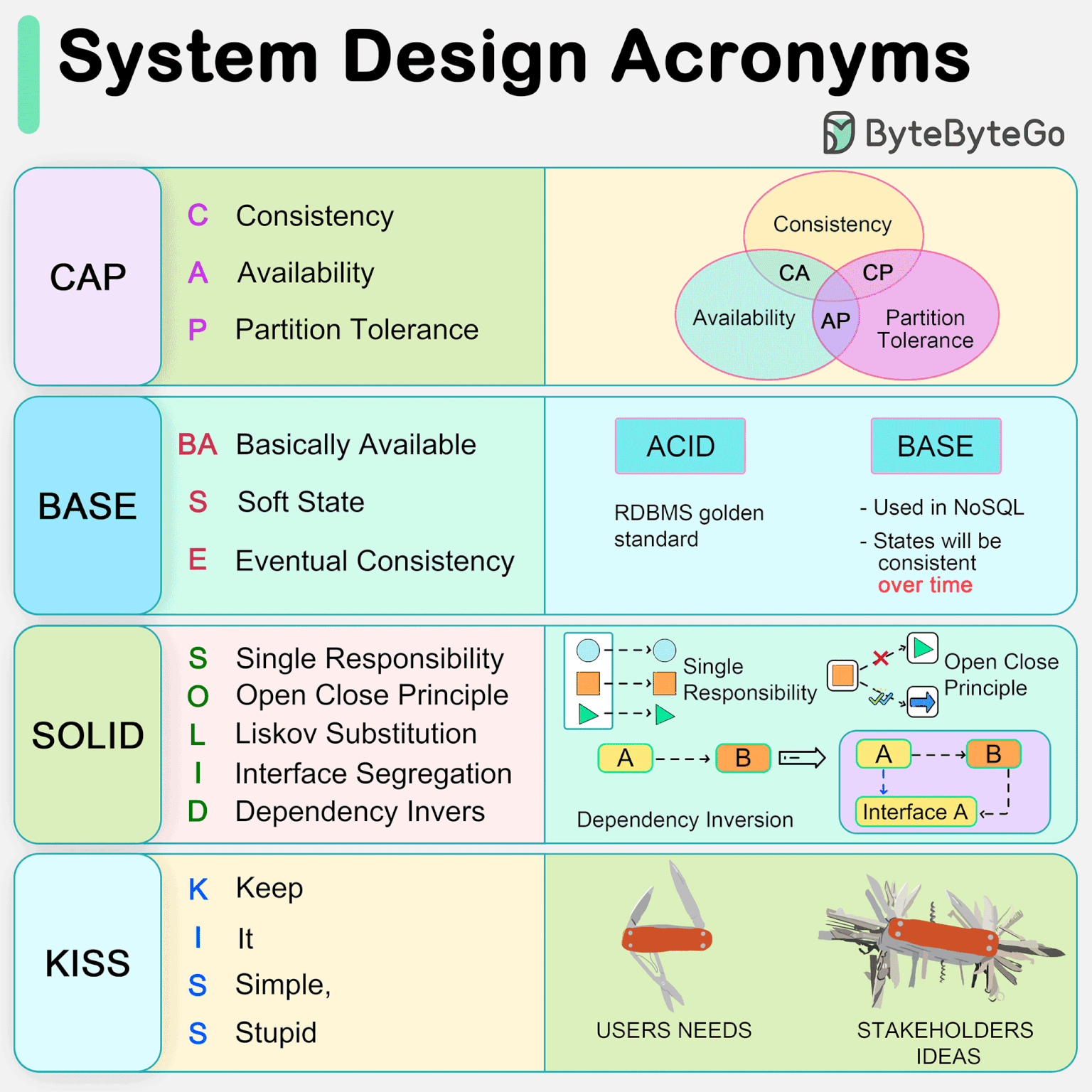
CAP: nhất quán hay sẵn sàng
Định lý CAP nói rằng khi mạng giữa các node bị chia cắt (partition), một hệ phân tán chỉ giữ được một trong hai: Consistency (mọi node thấy cùng dữ liệu mới nhất) hoặc Availability (mọi request vẫn được trả lời).
Khi không có partition thì không phải chọn. Khi có partition, hệ CP từ chối phục vụ phần bị nghi ngờ để giữ dữ liệu đúng. Hệ AP vẫn trả lời nhưng chấp nhận dữ liệu có thể cũ. Ngân hàng chọn CP. Mạng xã hội thường chọn AP.
The CAP theorem says that when the network between nodes is split (a partition), a distributed system can keep only one of two things: Consistency (every node sees the same latest data) or Availability (every request still gets an answer).
With no partition there is no choice to make. During a partition, a CP system refuses to serve the doubtful part to keep data correct. An AP system keeps answering but accepts possibly stale data. Banks pick CP. Social feeds usually pick AP.